The Time I Uploaded 3000 videos to YouTube
Table of Contents
- Synopsis
- The goal
- Nailing the goals one by one
- What did I get wrong
- What did I get right
- What did I learn
- Where to from here
Synopsis
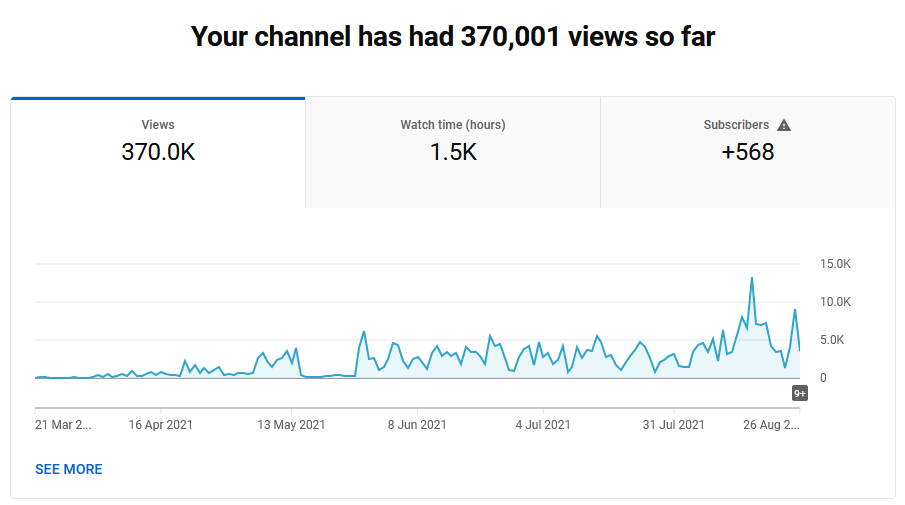
The story of the automation journey I went on to create an entire YouTube channel with 3000 videos, over 300,000 views and over 500 subscribers in 6 months. (PS. I didn’t advertise or cheat for subs or views)
A completely true and not too sensationalist title for my project that got a bit out of control and while it was meant to be a man automating the machine project, at some points, I felt like I was a cog doing the machines work.
If you would prefer to watch me talking about this article and the project.
The Goal
I had an idea about automation and news. I had a simple premise that I could programmatically create a daily video showcasing a lot of different news articles from different sources for the day. The idea was about curating content from the web, summarising pertinent facts and putting it all together in a news show type format, content on one side and someone on the side talking through it as if it was a real person.
Here is the channel I built
https://www.youtube.com/c/TonyTechnology

A popular video early on which made me think the project had more legs
The Pieces I needed to cover
- Find interesting articles
- Create a video of the article for something to look at
- Create a summary of the article for something to read
- Text to speech the summarised article
- Create a machine learning model of a human head talking to the video
- Put all the bits together to make it work.
Find interesting articles
Initially I was looking at HackerNews and thought it would be great to highlight some of their articles, I quickly found an API that they allow access to and was able to grab some interesting articles. After the initial work on this, I built an RSS reader which was able to iterate through the articles and create the video. On the back of this, I found the Google Search Alerts, which are able to create RSS feeds for searches, which was great for finding content dynamically from around the web based around a search term.
https://github.com/HackerNews/API
https://en.wikipedia.org/wiki/RSS

Create a video of the article for something to look at
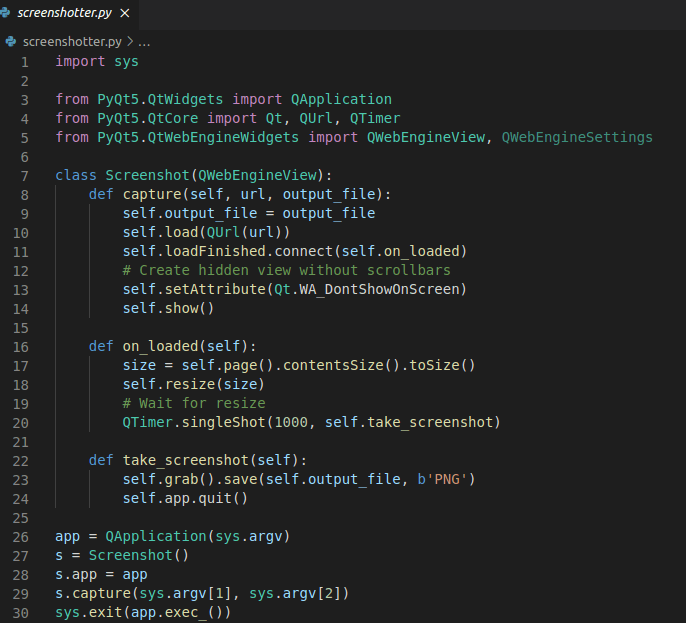
I had hoped to find something off the shelf to do this which I could easily integrate, but I actually ended up rolling up something pretty custom. On a unix machine I start up the QT browser engine and then create a very high quality screenshot of the website, once I have that I can create a scrolling video using the image as an input to ffmpeg with some fancy options.
Create a summary of the article for something to read
Once again some quick searches got me to an awesome python library which was able to summarise articles for me. I provide full text to the summariser and it returns suggested content. There was a bit of tuning back and forth and eventually I found a sweet spot for generating content which was under 60 seconds long per article using the title then a 2 sentences summary
Here’s an example of the generated description along with the video creation process. The first line is the title, I then provide the link for attributation, and then the automatically generated summary and finally some more details about where the article came from and finally the #Shorts tag for YouTube, which was originally needed to flag videos for Shorts, but I don’t believe it is anymore.
Electric cars have much lower life cycle emissions, new study confirms
https://arstechnica.com/?p=1784275
If you listen to electric vehicle naysayers, switching to EVs is pointless because even if the cars are vastly more efficient than ones that use internal combustion engines—and they are—that doesn't take into account the amount of carbon required to build and then scrap them.Advertisement Assuming the four regions stick to officially announced decarbonization programs, in 2030 the gap widens in favor of BEVs, even accounting for more efficient engine technologies and fuel production.
Found via Ars Technica RSS Feed :
https://feeds.arstechnica.com/arstechnica/index
Check it out for this and other awesome articles
#Shorts
Text to speech the summarised article
Carrying on with the process of finding interesting python modules, I found a great one to take my audio and convert it into speech, it’s free and provided by Google and has a very slow and unique voice that I find infuriatingly easy to listen to. It’s very understandable and is easy to use, but has literally no customisation. There’s some amazing research going on in this area and I tried about 20 different text to speech engines that I could run locally on my machine and while some where super customisable and others sounds phenomenal, none of them was as good as slowly and methodically sounding out the words one at a time like the first TTS engine I tried.
Speech Generation in use
Prototype not in use (Better voice but worse vocabulary)
Basically Core eee5 vs Core I5 broke me, I couldn’t switch, there’s Ram later vs R-A-M which was the 2nd nail in the coffin.
I did some very fun work with finding out about languages and phonemes and actually tried to build my own text to speech engine from my voice. I recorded long spoken paragraphs of my voice onto my PC and then used some speech to text libraries to identify the phonemes I was saying in each work and snuck the pieces into separate files, which I would add back together later. Using a text string and identifying the phonemes in the word, I could grab each of these discrete little sounds and put it back together to form the words I wanted. It was honestly one of the scariest things I’ve heard, if you can imagine a ransom letter with the different letter cutouts from a magazine as a voice, this was it!
Word Level Speech Generation
Phoneme Level Speech Generation
I honestly still laugh at the horror of that above audio clip everytime I listen to it
Create a machine learning model of a human head talking to the video
I found some amazing research papers which let me generate a video of a person talking from a static image and an audio file. I think it looked amazing and added quite a lot of dynamic appeal to my videos, though the final consensus from 3000 videos and over 100,000 views was that I should remove it as it was in the uncanny valley, her one eye was always shut and it distracted from the comments. That is a profanity free, very short, summary of the comments I got about my ML speaking face!
The AI generated face, which was then animated by the ML algorithm to the audio

Talking head in action (same video as earlier)
This was an interesting part of the project and stumped a lot of my dockerization attempts. I initially got the ML code up and running on my windows machine with CUDA on Anaconda, which was surprisingly simple and easy, though proved for some reason impossible for me to port to a docker machine or my linux machine… I could have possibly put more effort into it, but with the comments and the snags I kept hitting, it was easier to ditch it in the end.
I replaced the talking head with a spinning logo and got no more snarky comments (for that!), WIN!

Put all the bits together to make it work.
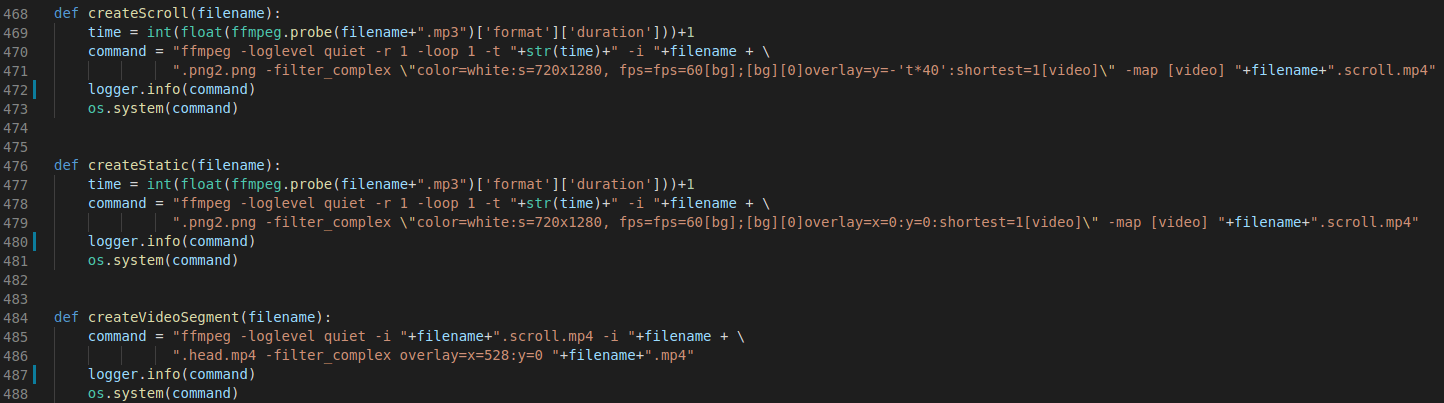
The glue code around everything ended up being mostly about breaking up the project into loosly coupled functional pieces of code, every step led into another step. Having the news articles led into creating the scrolling videos and summarising the content, straight into the audio generation and ML video generation.
What did I get wrong

I think the toughest bits were the things I didn’t do upfront and having to retrofit them later, things that stuck out were adding in a database later and trying to decouple the steps which were inherently tied into certain files existing on disk. The database seemed like overkill initially, but once I was processing 50 videos a day it became an intricate part of the process of monitoring and avoiding duplication.

That leads into monitoring itself, where I felt I had some failings initially, it’s something I thought I could wing my way through, but as always I was wrong, every bug ends up being 10 times harder to debug without logging, I’ll excuse myself slightly since it’s a personal project, but a small slap on the wrist to remember next time.

Dockerise upfront, I love local development, but keeping parity with a remote build is a great idea. Not losing track of dependencies and settings, it’s a bit hard to do when you’re in flux with development and proof of concepts, but remember to go back once you’ve got it working and make sure you get it working again.
What did I get right

Well I did manage to get over 500 subscribers and upload over 3000 videos to YouTube. I’m going to put those under the WIN! category for a small personal project.

I had a successful pivot before even going live, just after I started the project YouTube Shorts was just kicking off, which actually fitted the project really well and I decided to generate single short videos.


This was the first time I wrote a relatively large Python application and I decided to use FastAPI to drive it. FastAPI is amazing, and it was so much fun to work with. I will definitely be using it on future projects. It was easy, intuitive and worked great out of the box, I can see myself writing services using FastAPI for strict domain boundaries and trying to build out functionality in independant pieces I may re-use in the future.

Breaking up the project into snippets and loosely coupling them made things more mentally manageable early on and moved faster later on. For instance I added features later to skip certain websites, because they never resulted in good scrolling videos cough Twitter and BBC cough Tagging was a fun feature that snuck in quite easily, just a list of words that were searched for, then added to the start of the description with a hash. By neccesity I added banned words to avoid getting a strike on the account, merely posting an article that mentioned the word sex, got me a community strike for a week, which killed all my YouTube Short traffic, even with me contesting it and getting it over turned.
What did I learn
I learnt some cool stuff about Python and FastAPI, like setting it up and running it, a lot of learning around what NOT to do from the async perspective.
I set up a Telegram bot for the first time, which was quite cool. I can ask it to give me videos of website articles and it does! This was going to tie into a submission mechanism, which I could do technically, but it wasn’t actually necessary for me to feed news in.
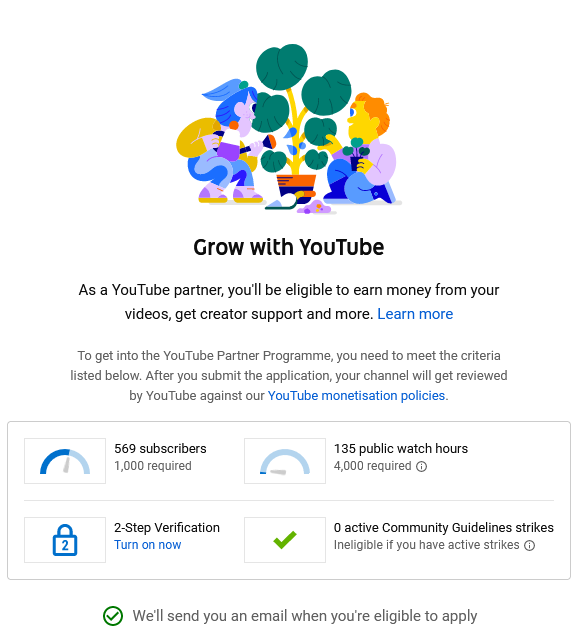
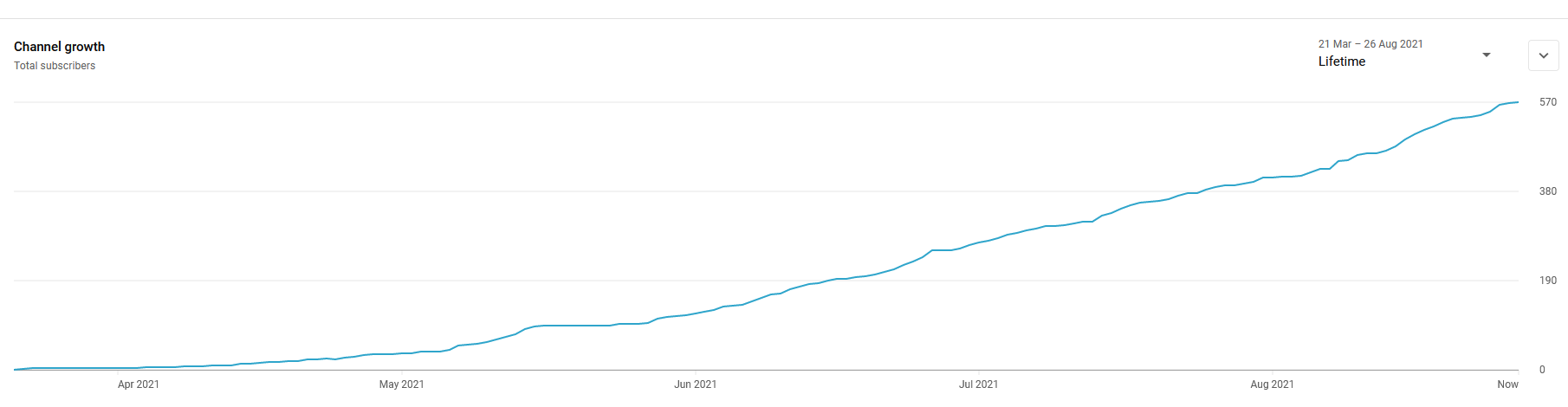
It was really interesting running and managing a YouTube channel and seeing what it would take to organically grow it, it’s been almost 6 months since I started the project and I only have half the subs I would need to monetize and because Short view time doesn’t count, not enough hours by a long way, since 90% of my traffic is shorts.
Even with over 1000 hours on record, only 100ish was not from Shorts, which is excluded.
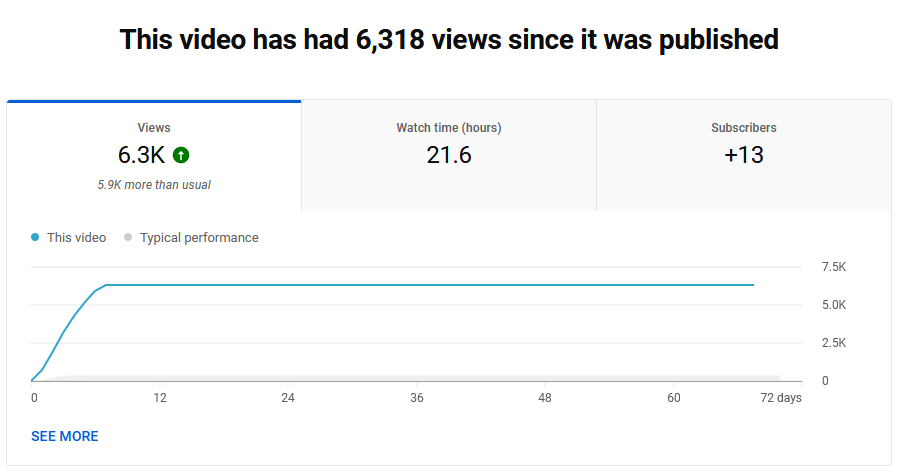
News articles don’t really generate a lot of continued view uptick after their initial spike in the zeitgeist
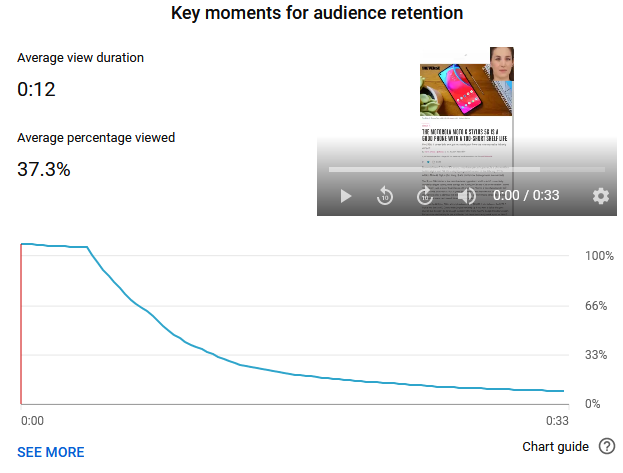
The shorts don’t really make people stick around that long, I swear I get swiped left quite quickly quite often, but I am personally a bit ruthless when I do these things too
YouTube API’s are great feature wise, but very restrictive with point allocations, you can only upload very few videos a day with the API and it was quite pedantic about making me sign in almost every time I used it, so while I got it working, I did give up on it soon in, due to the amount of videos I wanted to upload daily. I was at one point doing manual uploads, then name matching my videos to update the titles and descriptions, because it used less points per call, it really felt a bit draconian.

I can say that I got really good at dragging and dropping 15 videos at a time into the YouTube upload and then slamming through titles and descriptions, that was me being a cog for the machine for a long portion of the project. After the initial couple hundred videos I was curious about increasing subscription rates and for a long time I was putting on End Cards with a subscription button and a popular article, eventually I swapped my channel watermark for a subscription button and that really made the uploads quicker and easier to manage.

What were the video hits and misses
I felt like I was really at the mercy of the algorithm, you always hear the popular YouTubers talk about it and yeah I’m not on the same scale, but it felt really random when a video would hit or not hit. With that said, the Tesla and SpaceX videos which I grab specifically from a Google RSS feed actually generate a lot of popular articles from anything that gets indexed by Google.
Where to from here
I think I’m close to closing the project out, I was really happy with the time I spent on it learning about Python, Bash Scripting, FFMPEG, Machine Learning frameworks, YouTube, Docker, Text to Speech Engines and driving the operating system with automation like Selenium and QT scripts.
It was a lot to take in and I think I’ll carry quite a few things onto the next project, I don’t think I’m quite ready to take on the YouTube world as a paid monetised creator, but it was definitely a fun few steps in that direction.
Thanks for reading this far and here’s how close I’ve come to the YouTube monetised creator goal as of near end of August 2021!
And finally if you read this far, some inception! Here’s an auto-generated video of this article.